

Introduction to Next Word Prediction
Next word prediction is a powerful language modeling task in machine learning. The goal of this task is to predict the most likely word (or sequence of words) that follows a given input context. It relies on statistical patterns and linguistic structures to generate predictions based on the provided context. For example, when typing a message on your phone, the predictive text feature suggests the next word, making typing faster and more efficient. Similarly, search engines predict search queries based on what you’ve typed, helping you find what you’re looking for more quickly.
Next word prediction models have a wide range of applications, including improving user experience in virtual assistants, smart keyboards, and chatbots, as well as powering features in search engines and auto-completion systems.
Process of Building a Next Word Prediction Model
To build an accurate and effective Next Word Prediction model, we need to follow a series of steps:
- Data Collection: Collect a diverse and large dataset of text documents. The quality and variety of your dataset play a crucial role in the performance of your model.
- Data Preprocessing: Clean and tokenize the data to prepare it for modeling. Tokenization is the process of converting text into a sequence of numbers, where each word is represented by a unique number.
- Feature Engineering: Engineer features such as word embeddings, which represent words in a high-dimensional space based on their meanings. This helps the model understand relationships between words.
- Model Selection: Choose an appropriate model for the task. Popular models for this task include Long Short-Term Memory (LSTM) and transformer-based models like GPT.
- Model Training: Train the model on the dataset, tuning hyperparameters to ensure optimal performance.
- Model Improvement: Continuously improve the model by experimenting with different techniques and architectures, such as adding more layers or using pre-trained word embeddings.
Step-by-Step Guide: Building the Model
In this section, I’ll walk through the process of building a Next Word Prediction model using Python and deep learning techniques, specifically with the help of the TensorFlow library.
1. Import Necessary Libraries
import numpy as np import tensorflow as tf from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Embedding, LSTM, Dense
2. Read and Prepare the Dataset
Start by loading your dataset. In this case, I will use a text file containing Sherlock Holmes stories.
# Read the text file
with open('content/sherlock-holm.es_stories_plain-text_advs.txt', 'r', encoding='utf-8') as file:
text = file.read()
3. Tokenize the Text
Next, I tokenize the text using Keras’s Tokenizer, which converts the text into a sequence of integers.
tokenizer = Tokenizer() tokenizer.fit_on_texts([text]) total_words = len(tokenizer.word_index) + 1
4. Create Input-Output Sequences
I now split the text into sequences of words. Each sequence represents a context, and the model will predict the next word in the sequence.
input_sequences = []
for line in text.split('\n'):
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
5. Padding the Sequences
Since the length of input sequences may vary, we need to pad them to ensure that all sequences have the same length.
max_sequence_len = max([len(seq) for seq in input_sequences]) input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
6. Split Data into Input and Output
Once the sequences are ready, we split them into input (X) and output (y) arrays.
X = input_sequences[:, :-1] y = input_sequences[:, -1] y = np.array(tf.keras.utils.to_categorical(y, num_classes=total_words))
7. Build the Model
I now build the model using an embedding layer, an LSTM layer, and a dense layer with a softmax activation to predict the next word.
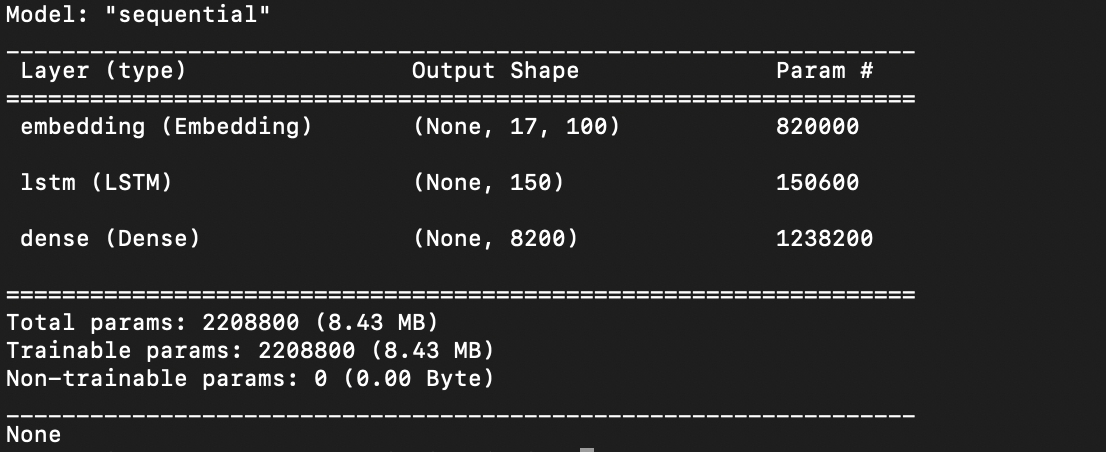
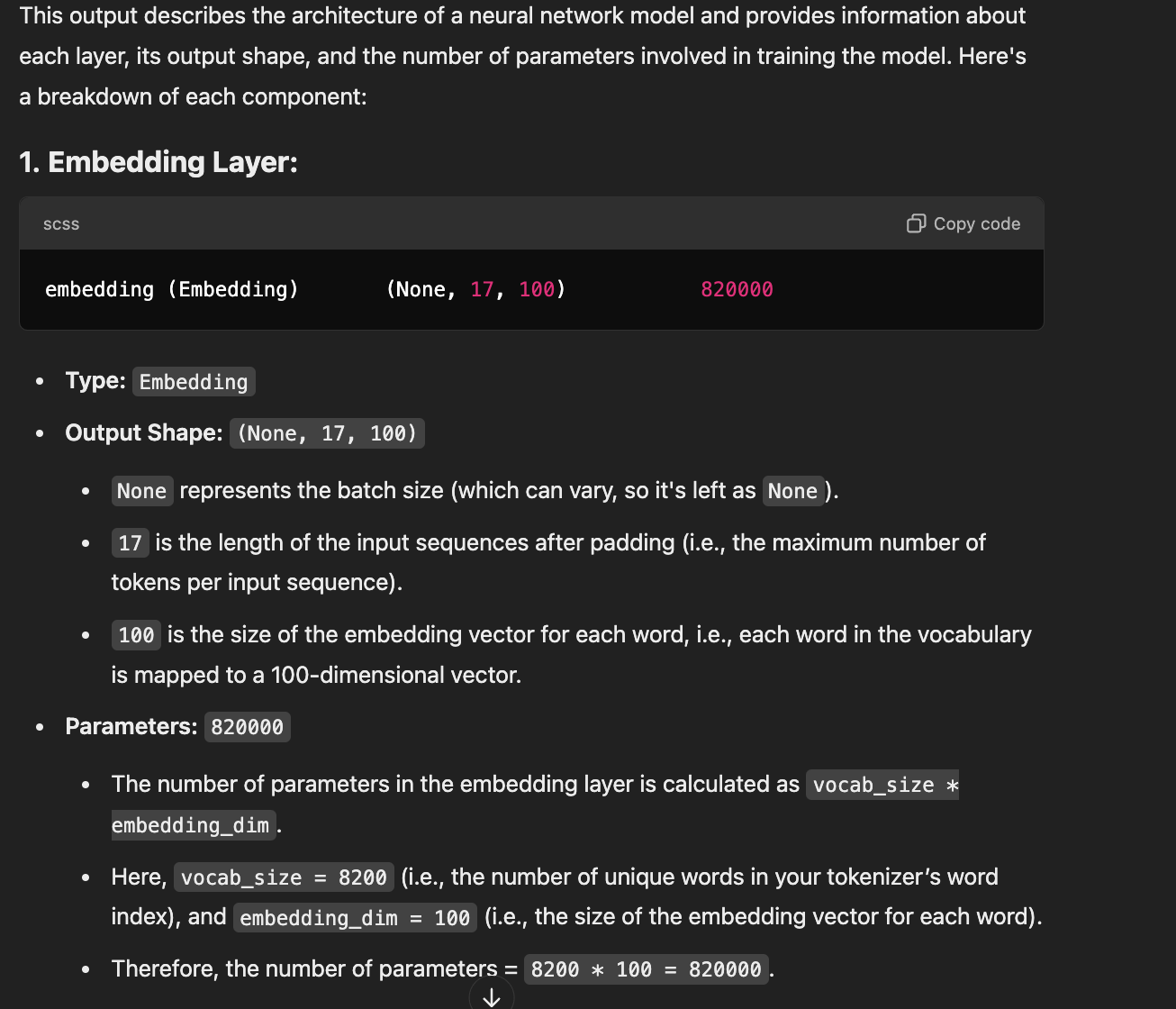
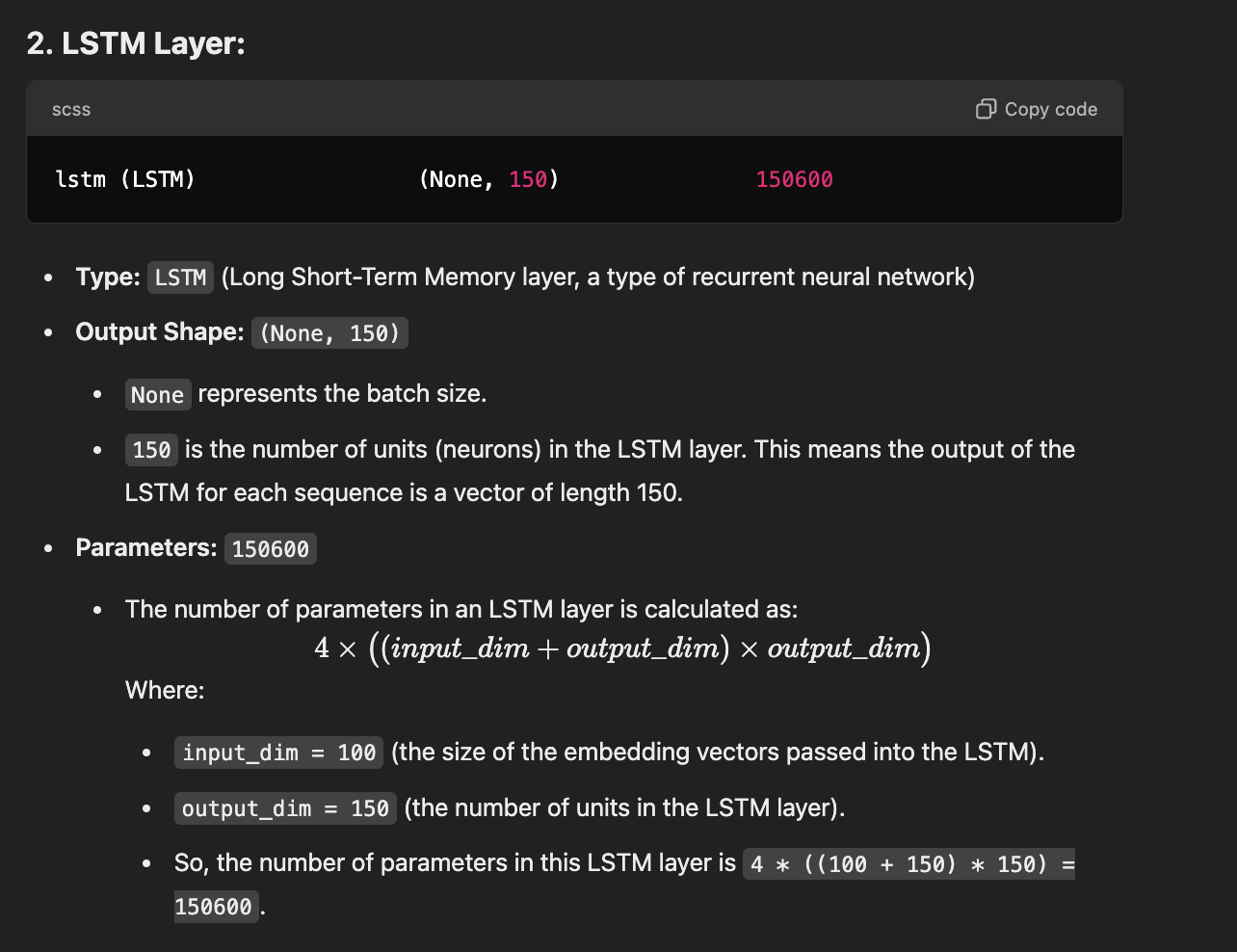
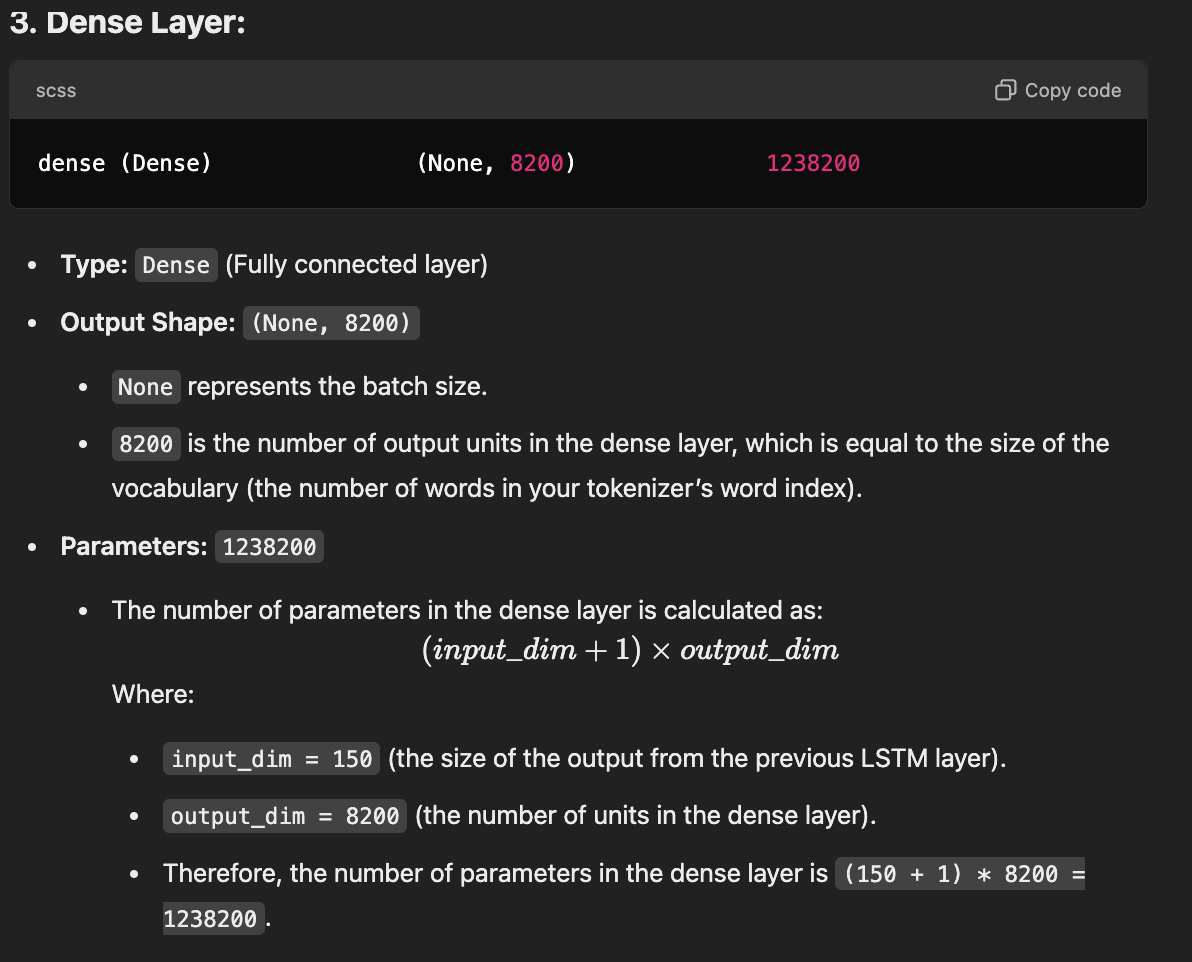
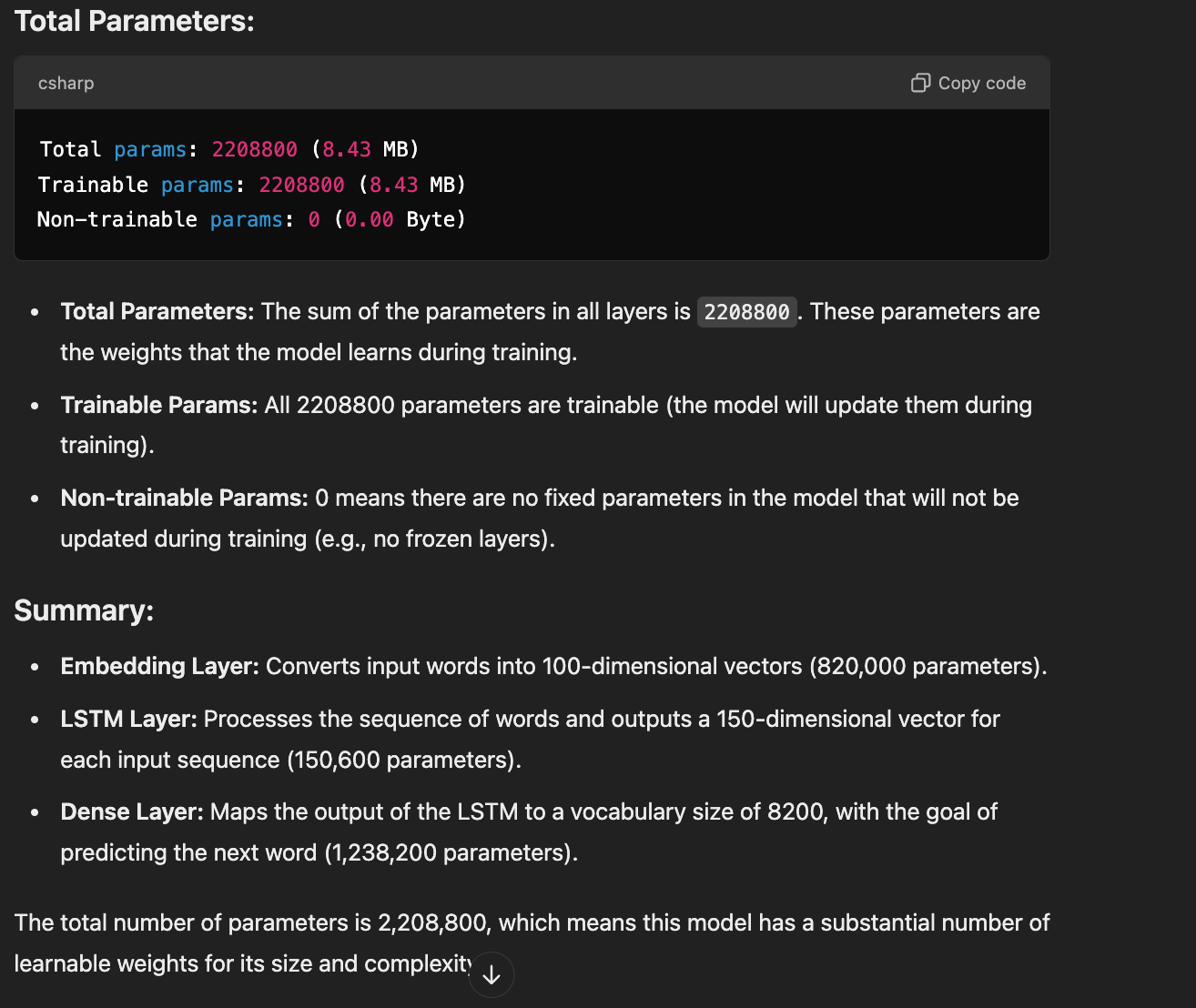
model = Sequential() model.add(Embedding(total_words, 100, input_length=max_sequence_len-1)) model.add(LSTM(150)) model.add(Dense(total_words, activation='softmax')) print(model.summary())
8. Train the Model
I compile and train the model using the categorical crossentropy loss function and the Adam optimizer.
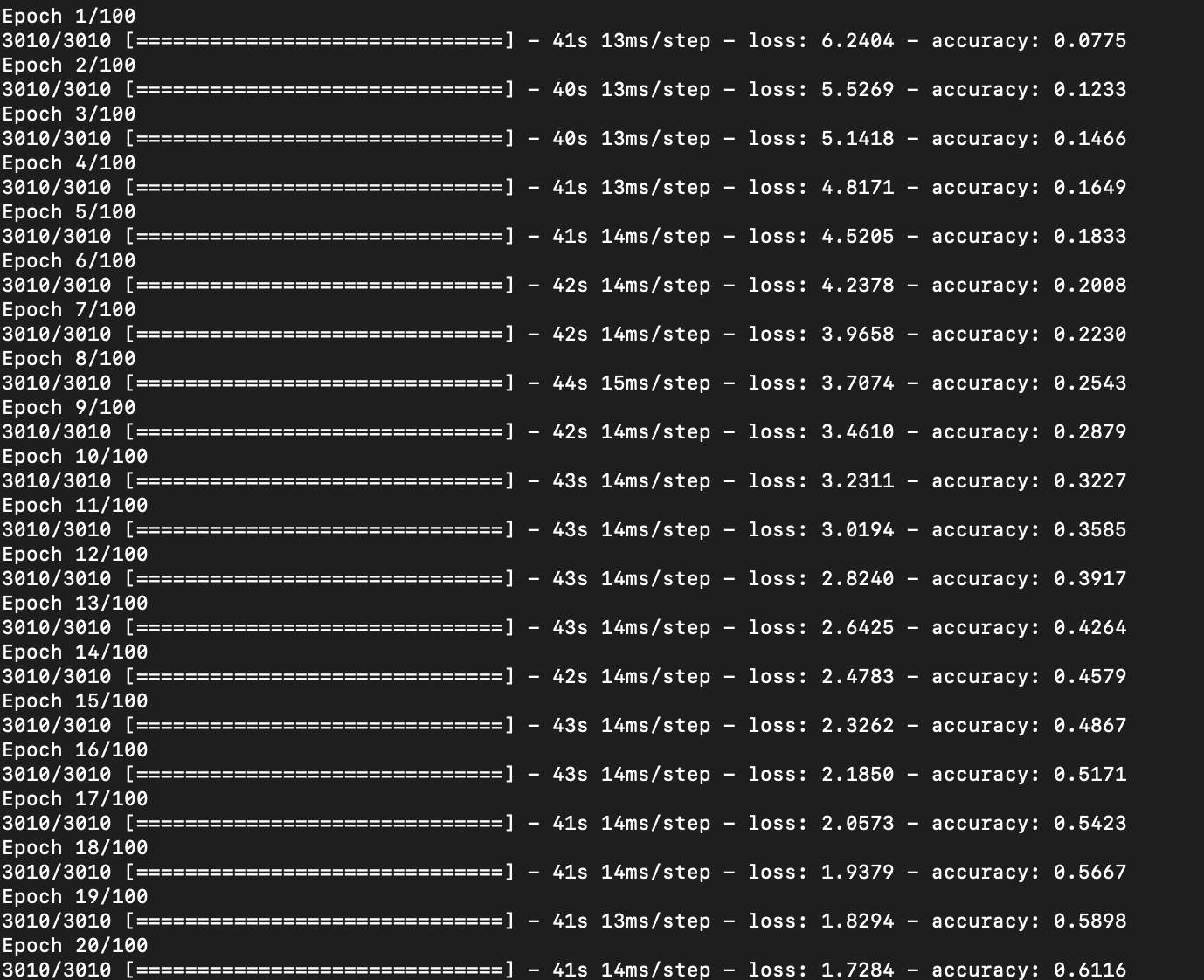
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(X, y, epochs=100, verbose=1)
9. Save the Trained Model
Once the model is trained, I save it for later use.
model.save('text_generation_model.h5')
print("Model saved as 'text_generation_model.h5'")
10. Load the Model and Make Predictions
To make predictions, I load the saved model and use it to predict the next words based on a given seed text.
# Load the saved model
loaded_model = tf.keras.models.load_model('text_generation_model.h5')
print("Model loaded successfully")
# Define seed text and the number of words to predict
seed_text = "I will leave if they"
next_words = 3
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
predicted = np.argmax(loaded_model.predict(token_list), axis=-1)
output_word = ""
for word, index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
seed_text += " " + output_word
print(seed_text)

Summary
In this blog post, I’ve walked through the process of building a Next Word Prediction model using deep learning and Python. I started by collecting a dataset, preprocessing it, and then building and training the model using TensorFlow. Finally, I saved the trained model and demonstrated how to load it for making predictions.
Next word prediction is an exciting application of machine learning, and it has a wide range of real-world uses, such as text suggestion in smartphones and search engines. By following this process, you can build your own language models and enhance your applications with powerful predictive capabilities.
Source Code can be found: https://github.com/arzerin/machine-learning/blob/main/prediction/next_word.py
Feel free to leave your thoughts or ask questions in the comments section below!
There are 0 comments